FinOps für AI: Wie wir AI-Kosten unter Kontrolle bekommen
Warum Token zur neuen Kosteneinheit werden und wie Transparenz, Limits und befähigte Teams die Kontrolle sichern
Eine neue Kostendimension mit alten Mustern
Ein einzelnes Beispiel hat in der Branche für Aufsehen gesorgt: Ein AI-Berater berichtete dem Nachrichtenportal Axios, dass einer seiner Kunden innerhalb eines einzigen Monats rund eine halbe Milliarde Dollar verbrauchte, weil auf den AI-Lizenzen der Mitarbeiter keine Nutzungslimits gesetzt waren. Der Fall klingt extrem, und in dieser Größenordnung ist er die Ausnahme. Das zugrunde liegende Muster ist es nicht. In kleinerem Maßstab erleben es viele Unternehmen gerade: Eine Rechnung springt von wenigen hundert auf mehrere tausend Euro im Monat, ohne dass im System ein Alarm anschlägt oder erkennbar ist, welcher Dienst oder welcher Nutzer den Anstieg verursacht hat.
Wer FinOps aus dem Cloudumfeld kennt, erkennt das Problem sofort wieder. Es ist nicht der einzelne teure Token, der die Kosten treibt, sondern die fehlende Sichtbarkeit und das Fehlen klarer Grenzen. Genau hier setzt FinOps an: Es verbindet betriebswirtschaftliche Steuerung mit operativer Transparenz, damit Fachbereiche, IT und Finanzbereich auf einer gemeinsamen Datengrundlage entscheiden können. Bei AI gilt dieselbe Logik. Die Kosteneinheit ist nur eine andere geworden.
Die gute Nachricht vorweg: Für diese Transparenz gibt es inzwischen einen offenen Standard. So wie sich Logs, Metriken und Traces im klassischen Monitoring etabliert haben, liefern die OpenTelemetry GenAI Semantic Conventions ein einheitliches Vokabular, um den AI-Verbrauch herstellerunabhängig zu erfassen und einzelnen Verursachern zuzuordnen. Dieser Standard ist der rote Faden, der sich durch die folgenden Abschnitte zieht, von der Zuordnung über die Architektur bis zum laufenden Controlling.
Kurz zusammengefasst beruht FinOps für AI auf fünf Hebeln: erstens Transparenz durch Token-Attribution, also die Zuordnung jedes Modellaufrufs zu Nutzer, Team und Feature; zweitens ein AI-Proxy als zentraler Kontrollpunkt für den gesamten AI-Verkehr; drittens klare Limits und Leitplanken, die unkontrollierte Kosten verhindern; viertens kontinuierliche Optimierung durch die richtige Modellwahl, schlanke Aufrufe und Zwischenspeichern; und fünftens befähigte Teams, die ihre Kosten verstehen und verantworten. Die folgenden Abschnitte gehen diese Hebel der Reihe nach durch.
Token sind Geld: AI rechnet nicht wie klassische Software ab
Klassische Software wird meist pro Lizenz oder pro Seat abgerechnet. Die Kosten sind planbar und ändern sich selten zwischen zwei Abrechnungszeiträumen, und die Beschaffung läuft über einen klar definierten Einkaufsprozess. AI verhält sich anders. Hier ist die Kosteneinheit der Token, und Kosten entstehen bei jedem einzelnen Aufruf neu, abhängig von der Länge der Eingabe, der Länge der Antwort und dem gewählten Modell.
Entscheidend ist dabei eine Parallele zur Cloud, die viele unterschätzen: Die Kaufentscheidung ist im Unternehmen demokratisiert. So wie die Cloud die Beschaffung von Infrastruktur aus dem Einkauf in die Hände der Entwicklung verlagert hat, verteilt AI die Ausgabenhoheit noch feiner. Nicht mehr eine zentrale Stelle entscheidet über Kosten, sondern jeder Entwickler löst mit jedem Prompt, jeder Modellwahl und jedem gestarteten Agenten reale Ausgaben aus. Die Frequenz, mit der kostenwirksame Entscheidungen getroffen werden, ist damit um Größenordnungen höher als bei klassischer Software.
Besonders ausgeprägt wird der Effekt bei agentischen Workflows, also bei AI-Systemen, die mehrschrittige Aufgaben eigenständig abarbeiten. Solche Abläufe verbrauchen ein Vielfaches eines einzelnen Modellaufrufs, weil sie in Schleifen arbeiten, Kontext immer wieder mitführen und Zwischenschritte erzeugen. Ein einzelner unbedachter Loop oder ein nicht begrenzter Hintergrundjob kann so in kurzer Zeit erhebliche Kosten verursachen. Während eine Cloud-Fehlkonfiguration ihre Wirkung oft über Tage entfaltet, kann ein außer Kontrolle geratener Agent innerhalb von Minuten kostspielig werden.
Damit verschiebt sich die zentrale Frage. Sie lautet nicht mehr, ob AI genutzt werden soll, sondern wie sich der Verbrauch sichtbar machen, einzelnen Verursachern zuordnen und im Bedarfsfall begrenzen lässt.
Von Cloud-Tagging zu Token-Tagging
Der wichtigste Gedanke für Entscheider lautet: AI-Kostenkontrolle ist kein vollständig neues Problem. Es ist FinOps mit einer feineren Granularität und einer deutlich höheren Geschwindigkeit. Wer im Cloudumfeld bereits eine Tagging-Strategie etabliert hat, besitzt die entscheidende Denkweise schon. Sie muss nur auf die neue Kosteneinheit übertragen werden.
Im Cloud-FinOps ordnen wir jede Ressource über Tags wie Kostenstelle, Team, Umgebung oder Projekt zu. Genau dieselbe Disziplin braucht AI, nur dass die Tags jetzt an jedem Modellaufruf hängen: Nutzer, Team, Feature oder Workflow. Ohne diese Zuordnung zum Zeitpunkt des Aufrufs lässt sich die spätere Sammelrechnung des Anbieters nicht mehr aufschlüsseln. Anomalien lassen sich nicht erklären, und der Geschäftswert eines einzelnen Features lässt sich nicht berechnen.
Drei Parallelen sind dabei besonders aufschlussreich. Erstens ist das größte praktische Problem in beiden Welten die Abdeckung. In jedem Cloud-Projekt sind anfangs erhebliche Teile der Ressourcen nicht getaggt und landen in einem nicht zugeordneten Sammelposten. Bei AI stellt sich dieselbe Frage: Trägt wirklich jeder Aufruf eine Identität? Zweitens liegt der Hebel in beiden Fällen in der Durchsetzung an der Quelle. In der Cloud bedeutet das, dass eine nicht getaggte Ressource gegen eine Richtlinie verstößt. Bei AI bedeutet es, dass ein Aufruf ohne Zuordnung gar nicht erst durchgelassen wird. Drittens entsteht der eigentliche strategische Vorteil, wenn dieselbe Taxonomie über beide Welten läuft. Dann lässt sich erstmals beantworten, was ein Feature insgesamt kostet, also Infrastruktur und AI zusammen. Genau diesen gemeinsamen Nenner verfolgt die FinOps Open Cost and Usage Specification, kurz FOCUS, die zunehmend auch AI-Verbrauchsdaten in ein einheitliches Format bringt und damit den natürlichen Anschluss an bestehende Werkzeuge wie Apptio bildet.
Wie diese Bausteine zusammenspielen, zeigt die folgende Architektur im Überblick, bevor wir die einzelnen Teile genauer betrachten.
 Abbildung: Bausteinsicht des AI-Proxy — links die Konsumenten, in der Mitte der Proxy mit den Modulen für Identität, Verbrauchsmessung, Limits, Routing und Telemetrie-Export, rechts die Anbieter inklusive On-Prem, darunter Dash0 als Auswertungssystem
Abbildung: Bausteinsicht des AI-Proxy — links die Konsumenten, in der Mitte der Proxy mit den Modulen für Identität, Verbrauchsmessung, Limits, Routing und Telemetrie-Export, rechts die Anbieter inklusive On-Prem, darunter Dash0 als Auswertungssystem
Sichtbarkeit zuerst: ein Standard für AI-Telemetrie
Bevor optimiert werden kann, muss gemessen werden. Wie eingangs erwähnt, hat sich dafür mit den OpenTelemetry GenAI Semantic Conventions ein offener Standard etabliert. Konkret definieren sie ein einheitliches Vokabular für AI-Telemetrie, etwa für das verwendete Modell, den Anbieter, die Art der Operation sowie den Verbrauch an Eingabe- und Ausgabe-Token. Der Vorteil für Unternehmen ist erheblich. Wer einmal auf diesem Standard instrumentiert, ist nicht an einen einzelnen Anbieter gebunden, sondern kann die Daten frei dorthin senden, wo sie ausgewertet werden sollen.
Für die Zuordnung der Kosten zu einzelnen Nutzern kommen zu diesen standardisierten Feldern die eigenen fachlichen Attribute hinzu, also Nutzerkennung, Team, Feature oder Kostenstelle. An genau diesen Merkmalen wird später aggregiert. Es ist dieselbe Idee wie die TraceID oder CorrelationID im klassischen Logging, mit der sich ein Eintrag eindeutig einem Request oder Geschäftsprozess zuordnen lässt. Nur dass die Kennung hier nicht der Fehlersuche dient, sondern der wirtschaftlichen Zuordnung.
In der Praxis sieht das so aus, dass jeder Modellaufruf in einen Span gehüllt wird, der die standardisierten Felder und die eigenen Zuordnungsmerkmale trägt:
from opentelemetry import trace
tracer = trace.get_tracer("ai-proxy")
with tracer.start_as_current_span("chat") as span:
# Standardisierte GenAI-Attribute (OpenTelemetry Semantic Conventions)
span.set_attribute("gen_ai.operation.name", "chat")
span.set_attribute("gen_ai.provider.name", "anthropic")
span.set_attribute("gen_ai.request.model", "claude-sonnet-4-6")
# Eigene Zuordnungsmerkmale — die Basis jeder Kostenaufschlüsselung
span.set_attribute("enduser.id", "k.herings")
span.set_attribute("team.name", "customer-support")
span.set_attribute("feature.name", "support-rag")
span.set_attribute("cost_center", "CC-4711")
response = client.messages.create(...)
# Verbrauch nach dem Aufruf festhalten
usage = response.usage
span.set_attribute("gen_ai.usage.input_tokens", usage.input_tokens)
span.set_attribute("gen_ai.usage.output_tokens", usage.output_tokens)
Die gen_ai.*-Felder folgen dem offenen Standard und sind damit über jedes kompatible Auswertungssystem hinweg gleich. Die Felder wie enduser.id oder team.name sind die fachliche Ergänzung, an der sich die Rechnung später nach Nutzer, Team oder Feature aufschlüsseln lässt. Wichtig ist, dass diese Zuordnung beim Aufruf gesetzt wird, denn nachträglich lässt sie sich aus der Sammelrechnung des Anbieters nicht mehr rekonstruieren.
Ein wichtiger Hinweis aus Datenschutzsicht: Für reines Kosten-Monitoring müssen keine Prompt-Inhalte gespeichert werden. Es genügen die Metadaten, also Token-Zahlen, Kosten, Modell, Latenz und die Zuordnungsmerkmale. Gerade für Unternehmen mit hohen Anforderungen an Datenschutz und Datenresidenz ist diese Trennung entscheidend.
Ein zentraler Kontrollpunkt: der AI-Proxy
Die praktikabelste Architektur, um Sichtbarkeit und Kontrolle zusammenzubringen, ist ein zentraler Durchgangspunkt für den gesamten AI-Verkehr, häufig als AI-Gateway oder AI-Proxy bezeichnet. Statt dass jede Anwendung direkt mit den Anbietern spricht, läuft der Verkehr über diesen einen Punkt. Anwendungen und Werkzeuge wie Entwicklungsumgebungen, Chat-Oberflächen, agentische Pipelines oder eigene Dienste erhalten dabei keine echten Anbieter-Schlüssel, sondern virtuelle Schlüssel, die intern auf Nutzer, Team oder Kostenstelle abgebildet sind. Jeder Aufruf wird damit automatisch zugeordnet, ohne dass der einzelne Entwickler etwas zusätzlich tun muss. Die zuvor gezeigte Bausteinsicht macht deutlich, wie Messung und Durchsetzung in diesem einen Baustein zusammenkommen.
Der entscheidende Punkt ist, dass die Messung und die Durchsetzung im selben Baustein sitzen. Der Proxy erfasst Verbrauch, Modell, Kosten und Latenz, setzt Limits durch, kann einfache Aufgaben an kleinere Modelle weiterleiten und exportiert die Telemetrie nach dem offenen Standard an ein Auswertungssystem. Damit ist Transparenz keine nachgelagerte Auswertung am Monatsende mehr, sondern Teil jedes einzelnen Aufrufs. Ein erwünschter Nebeneffekt ist, dass auf diesem Weg auch bislang unkontrollierte Direktnutzung, die sogenannte Schatten-AI, in eine geordnete Umgebung überführt wird.
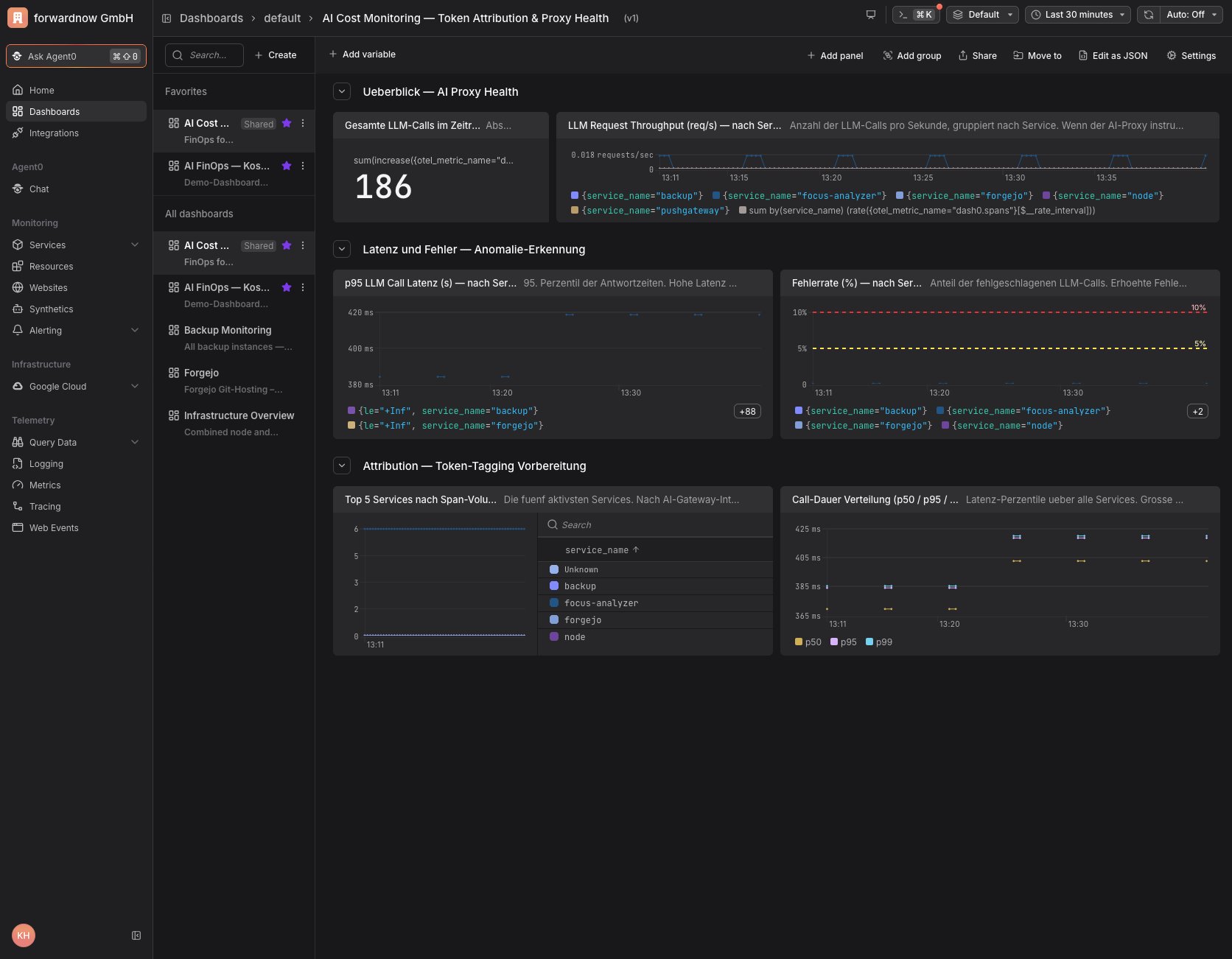 Abbildung: Gesundheit des AI-Proxy in Dash0 — Durchsatz, Latenz und Fehlerrate je Service als Grundlage für die Anomalie-Erkennung
Abbildung: Gesundheit des AI-Proxy in Dash0 — Durchsatz, Latenz und Fehlerrate je Service als Grundlage für die Anomalie-Erkennung
Limits und Leitplanken setzen
Sichtbarkeit allein verhindert keine Kostenexplosion. Sie ist die Voraussetzung dafür, dass sinnvolle Grenzen überhaupt definiert werden können. In der Praxis hat sich ein klares Reifegradmuster gezeigt. Teams führen zunächst Begrenzungen für die Anzahl der Anfragen ein, ergänzen nach der ersten Überraschungsrechnung Begrenzungen für den Token-Verbrauch und führen nach der zweiten ein hartes Budget-Limit pro Zeitraum und Team ein.
Diese Limits wirken auf mehreren Ebenen zusammen. Begrenzungen der Anfragezahl schützen die Infrastruktur. Token-basierte Begrenzungen steuern den eigentlichen Verbrauch, da Token direkt mit Rechenaufwand und Kosten zusammenhängen. Budget-Grenzen schließlich verhindern, dass unerwartete Lastspitzen aus Stapelverarbeitung oder Agenten-Schleifen zu untragbaren Rechnungen führen. Am Gateway lässt sich das je virtuellem Schlüssel deklarativ hinterlegen:
# Limits pro virtuellem Schlüssel (Beispiel: Team Customer Support)
key: support-rag
limits:
requests_per_minute: 120 # schützt die Infrastruktur
tokens_per_minute: 200000 # steuert den eigentlichen Verbrauch
budget:
period: monthly
soft_limit_eur: 5000 # weiche Schwelle → Alert
hard_limit_eur: 6000 # harte Grenze → Aufrufe werden abgewiesen
circuit_breaker:
cost_velocity_eur_per_min: 20 # stoppt Runaway-Agenten in Minuten
Besonders wirksam ist die Kombination aus weichen Schwellen, die frühzeitig warnen, und einem harten Sicherungsmechanismus, der bei einer auffälligen Kostengeschwindigkeit eingreift. Ein außer Kontrolle geratener Agent, der ein Vielfaches seines geplanten Budgets pro Minute verbraucht, wird so innerhalb von Minuten gestoppt und nicht erst Stunden später durch die Finanzabteilung entdeckt. Genau dieser Mechanismus fehlte in dem eingangs beschriebenen Fall.
Die richtigen Modelle und schlanke Aufrufe
Wenn Transparenz und Leitplanken stehen, beginnt die eigentliche Optimierung. Der konsistent größte Hebel ist die richtige Modellwahl. Nicht jede Aufgabe benötigt das größte und teuerste Modell. Im oben gezeigten Beispiel verursacht die größte Modellklasse einen Kostenanteil von 44 Prozent, obwohl sie nur 18 Prozent der Aufrufe ausmacht. Wenn ein Teil dieser Aufrufe an ein mittleres Modell weitergeleitet wird, sinkt der Durchschnittspreis deutlich, ohne die Qualität spürbar zu beeinträchtigen. In der Praxis lassen sich auf diese Weise erhebliche Anteile der Kosten einsparen.
Wie groß der Unterschied zwischen den Klassen ist, zeigt ein Blick auf die Listenpreise und die Kosten einer einzelnen Beispielanfrage:
 Abbildung: Kosten je Modellklasse — Listenpreise pro Million Token und die Kosten einer Beispielanfrage mit 10.000 Eingabe- und 2.000 Ausgabe-Token (Stand Juni 2026)
Abbildung: Kosten je Modellklasse — Listenpreise pro Million Token und die Kosten einer Beispielanfrage mit 10.000 Eingabe- und 2.000 Ausgabe-Token (Stand Juni 2026)
Die Zahlen machen den Hebel greifbar. Dieselbe Beispielanfrage kostet im größten Modell rund fünf Cent, in einem mittleren Modell rund sechs Cent und in einem kleinen Modell etwa zwei Cent. Zwischen einem Premium-Modell und einem Budget-Modell liegt damit je nach Anbieter ein Faktor von mehr als zehn. Bei wenigen Aufrufen ist das unerheblich, doch hochgerechnet auf Hunderttausende oder Millionen Aufrufe pro Monat entscheidet die Modellwahl maßgeblich über die Gesamtrechnung. Entscheidend ist deshalb nicht, das billigste Modell pauschal zu erzwingen, sondern jede Aufgabe an das günstigste Modell zu leiten, das die geforderte Qualität noch zuverlässig liefert. Diese Werte ändern sich im Markt regelmäßig, weshalb die Zuordnung als fortlaufende Aufgabe und nicht als einmalige Entscheidung zu verstehen ist.
Zwei weitere Hebel kommen hinzu. Schlanke Eingaben, also kürzere System-Anweisungen, begrenzte Ausgabelängen und ein bewusst reduzierter Kontext, senken den Verbrauch sofort. Und das Zwischenspeichern wiederkehrender Anfragen vermeidet, dass für dieselbe Frage immer wieder bezahlt wird. Bemerkenswert ist, dass sich bereits durch die Kombination aus Modellwahl, schlanken Aufrufen und Zwischenspeichern in vielen Projekten ein Einstiegsziel in der Größenordnung von dreißig Prozent Einsparung erreichen lässt. Es ist dieselbe Erfahrung, die wir aus Cloud-Optimierungsprojekten kennen.
On-Prem realistisch einordnen
Eine Frage, die in fast jedem Gespräch aufkommt, ist die nach dem Betrieb eigener Modelle, also On-Prem oder in der eigenen Cloud. Die intuitive Annahme lautet, dass eigener Betrieb günstiger sei. Ein ehrlicher Blick auf die Gesamtkosten relativiert das jedoch. Zur reinen Rechenleistung kommen Aufwände für Betrieb und Wartung, für ungenutzte aber bezahlte Kapazität, für Strom und Kühlung sowie für regelmäßige Modellaktualisierungen hinzu. Für die meisten Organisationen ist der Bezug über Schnittstellen daher zunächst die wirtschaftlichere Variante, solange das Verbrauchsvolumen nicht sehr hoch ist.
Der eigentliche Treiber für eigenen Betrieb ist daher selten der Preis, sondern Compliance und Datenhoheit. Wo regulatorische Anforderungen, Datenresidenz oder besondere Vertraulichkeit es verlangen, kann der eigene Betrieb die einzig zulässige Option sein, unabhängig von der reinen Kostenrechnung. In der Praxis ist häufig ein hybrider Ansatz sinnvoll, bei dem planbare und sensible Lasten lokal verarbeitet werden und der Rest über Schnittstellen abgedeckt wird. Wichtig ist, dass diese Entscheidung auf Basis belastbarer Verbrauchsdaten getroffen wird und nicht aus einem Bauchgefühl heraus. Auch hier ist Transparenz die Voraussetzung für eine fundierte Entscheidung.
Enablement: der eigentliche Erfolgsfaktor
Aus unserer FinOps-Erfahrung wissen wir, dass der nachhaltigste Effekt nicht aus dem Dashboard entsteht, sondern aus den Menschen, die die Kosten verursachen. Ein Team, das versteht, dass eine vergessene Umgebung oder eine überdimensionierte Ressource reales Geld kostet, trifft tausend kleine Entscheidungen besser. Bei AI gilt das in verschärfter Form, weil hier nicht eine einmalige Infrastrukturentscheidung den Ausschlag gibt, sondern jeder Entwickler bei jedem Aufruf eine Kostenentscheidung trifft: welches Modell, wie viel Kontext, ob ein Agent wirklich nötig ist.
Genau deshalb ist der Leitsatz jedes Trainings, dass der Token-Verbrauch ein Maß für Aktivität ist und nicht für Produktivität. Mehr Verbrauch ist kein Zeichen von Fortschritt, sondern ein Kostenfaktor, der sich rechtfertigen muss. Wie wichtig diese Unterscheidung ist, zeigt ein bekannt gewordenes Gegenbeispiel: Ein Konzern hatte intern eine Rangliste eingeführt, die den Token-Verbrauch von Entwicklern sichtbar machte. Das Ergebnis war, dass Mitarbeiter begannen, unnötige Aufgaben zu erledigen, um in der Liste zu steigen. Die Rangliste wurde wieder abgeschafft. Es war kein Werkzeugproblem, sondern ein Enablement-Problem, weil die falsche Kennzahl zur Tugend erklärt worden war.
Ein wirksames Programm setzt deshalb auf mehreren Ebenen an. Entwicklerinnen und Entwickler lernen eine praktische Kosten-Hygiene, also wann ein kleines Modell genügt, warum langer Kontext bei jedem Aufruf erneut kostet, was ein agentischer Ablauf tatsächlich verbraucht und wie sich die eigenen Kosten überhaupt ablesen lassen. Teamleitungen lernen, ihr Budget zu verstehen, Auswertungen zu lesen und Auffälligkeiten im eigenen Bereich zu erkennen, wobei Kostenbewusstsein als gemeinsame Verantwortung etabliert wird und nicht als Strafe. Und Entscheider lernen, sinnvolle Leitplanken zu setzen, ohne Innovation zu ersticken, und richtig zu incentivieren.
Daraus ergibt sich eine klare Reihenfolge, die das gesamte Vorgehen zusammenhält: Sichtbarkeit führt zu Problembewusstsein, und Problembewusstsein führt zu verändertem Verhalten. Ohne Sichtbarkeit gibt es kein Bewusstsein, und ohne Bewusstsein keine dauerhafte Verhaltensänderung. Das Dashboard ist dabei nicht das Ziel, sondern das Werkzeug, mit dem Menschen anfangen, Kostenentscheidungen zu sehen, die vorher unsichtbar waren.
Controlling als Daueraufgabe und der Werkzeugkasten
AI-Kostensteuerung ist kein einmaliges Projekt, sondern eine fortlaufende Praxis. Verbrauch, Modelle und Nutzungsmuster verändern sich, und damit muss sich auch die Steuerung kontinuierlich anpassen. Wichtig ist deshalb ein laufendes Monitoring, das Kosten nach Nutzer, Team und Feature aufschlüsselt, Anomalien erkennt und die Wirksamkeit der eingeführten Maßnahmen sichtbar macht.
In der Praxis unterstützen spezialisierte Werkzeuge diesen Prozess. Bevor wir auf das konkrete Werkzeug schauen, lohnt der Blick auf das Zielbild. Konzeptionell soll ein AI-Kosten-Dashboard auf einen Blick beantworten, wer wie viel verbraucht, wo nicht zugeordnete Kosten liegen, wo eine Anomalie auftritt und wie sich der Modell-Mix verteilt.
 Abbildung: Schematisches Zielbild eines AI-Kosten-Dashboards — Kosten nach Team mit einem nicht zugeordneten Sammelposten, ein Anomalie-Hinweis und der Modell-Mix als Routing-Hebel
Abbildung: Schematisches Zielbild eines AI-Kosten-Dashboards — Kosten nach Team mit einem nicht zugeordneten Sammelposten, ein Anomalie-Hinweis und der Modell-Mix als Routing-Hebel
Wie schon im klassischen Monitoring von Logs, Metriken und Traces lässt sich auch AI-Telemetrie an einem zentralen Ort bündeln und korrelieren. Eine Plattform wie Dash0 nimmt die standardisierten Telemetriedaten entgegen und erlaubt es, Kosten nach Nutzer, Team oder Feature aufzuschlüsseln, über die Zeit zu verfolgen und Auffälligkeiten frühzeitig den verantwortlichen Anwendungen zuzuordnen. Weil die Instrumentierung auf einem offenen Standard beruht, bleibt das auswertende System dabei austauschbar, was die Unabhängigkeit von einzelnen Anbietern bewahrt. Aus dem schematischen Zielbild wird so eine reale Auswertung:
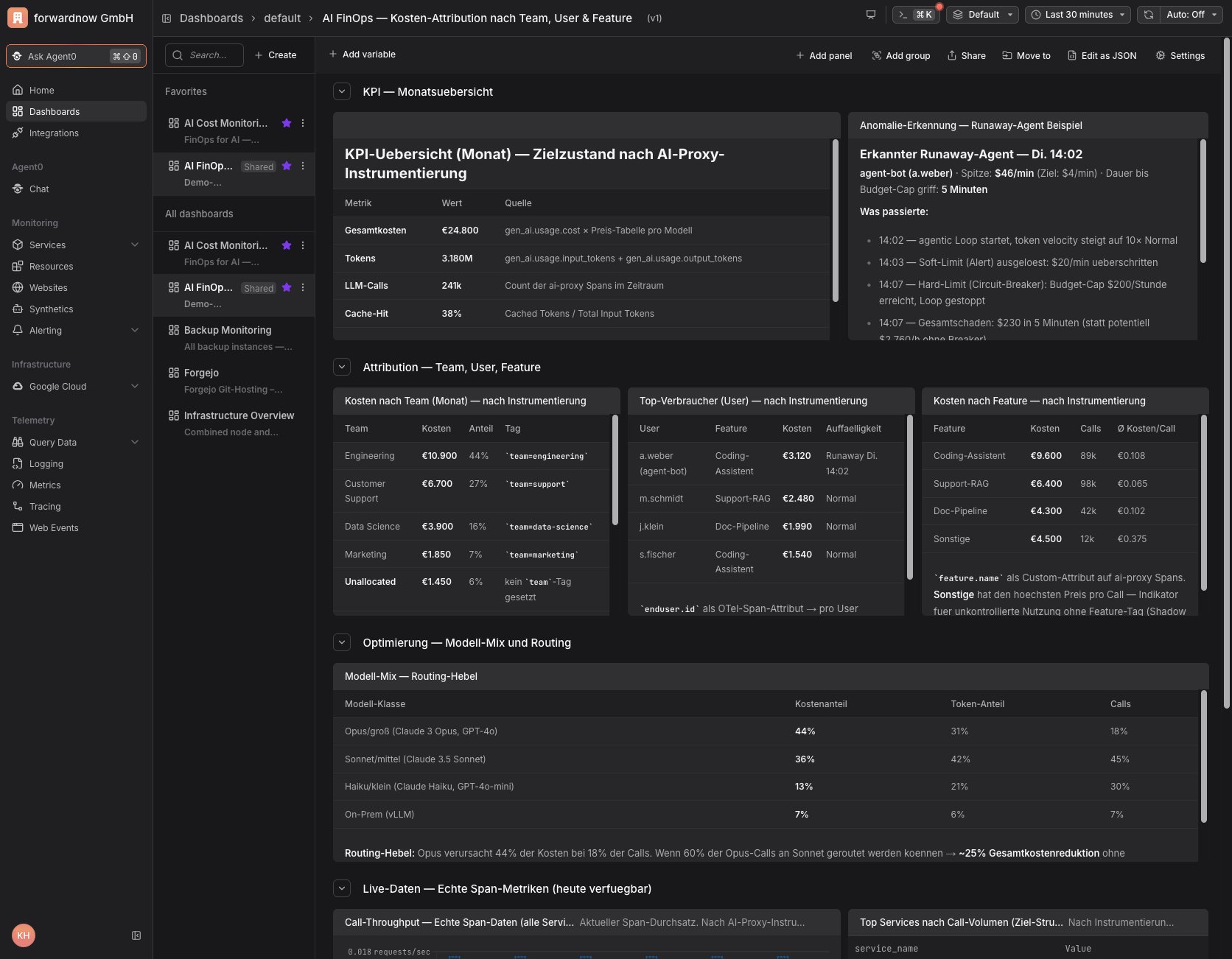 Abbildung: Kosten-Attribution in Dash0 — Aufschlüsselung nach Team, Nutzer und Feature, ein nicht zugeordneter Sammelposten als Kennzahl für die Abdeckung sowie ein Beispiel für einen erkannten Runaway-Agenten
Abbildung: Kosten-Attribution in Dash0 — Aufschlüsselung nach Team, Nutzer und Feature, ein nicht zugeordneter Sammelposten als Kennzahl für die Abdeckung sowie ein Beispiel für einen erkannten Runaway-Agenten
In diesem Beispiel werden mehrere der zuvor beschriebenen Prinzipien auf einen Blick sichtbar. Die Kosten lassen sich über das team-Attribut den verursachenden Bereichen zuordnen, während ein nicht zugeordneter Sammelposten zeigt, wie hoch der Anteil ohne gesetztes Tag ist und damit als Kennzahl für die Abdeckung dient. Die Aufschlüsselung nach Feature offenbart, wo die höchsten Kosten pro Aufruf entstehen, und der Modell-Mix macht den Routing-Hebel greifbar, indem er sichtbar macht, welcher Anteil der Kosten auf die größten Modelle entfällt. Das Beispiel eines erkannten Runaway-Agenten schließlich verdeutlicht, wie eine weiche Warnschwelle und ein hartes Budget-Limit zusammenwirken, um einen entgleisenden Ablauf innerhalb von Minuten zu stoppen.
Fazit
Die Steuerung von AI-Kosten ist kein grundlegend neues Feld, sondern die konsequente Erweiterung dessen, was FinOps im Cloudumfeld seit Jahren leistet. Die Kosteneinheit hat sich vom Ressourcenverbrauch zum Token verschoben, die Geschwindigkeit der Kostenentstehung ist gestiegen, und die Zahl der Beteiligten, die täglich Kostenentscheidungen treffen, ist deutlich größer geworden. Die wirksamen Hebel bleiben jedoch dieselben: Transparenz durch konsequente Zuordnung, klare Leitplanken durch Limits, kontinuierliche Optimierung durch die richtige Modellwahl und schlanke Aufrufe sowie, als entscheidender Faktor, befähigte Teams, die ihre Kosten verstehen.
Wenn Sie AI-Kosten nicht länger als unvermeidliche Nebenwirkung der Innovation behandeln möchten, sondern als steuerbare Größe in Ihrer FinOps-Praxis, lohnt sich der Blick auf die passende Architektur, sinnvolle Limits und ein durchdachtes Enablement-Programm. Kontaktieren Sie uns gerne für ein unverbindliches Gespräch. Gemeinsam prüfen wir, wie sich Ihre konkrete Situation analysieren lässt und welche Maßnahmen in Ihrem Unternehmen den größten Beitrag leisten.
Hinweis: Dieser Beitrag dient der Orientierung und gibt unsere Einschätzung zum Zeitpunkt der Veröffentlichung wieder. Preise, Modellnamen und technische Details im AI-Umfeld ändern sich schnell, und trotz sorgfältiger Recherche können einzelne Angaben Fehler enthalten oder inzwischen überholt sein. Die gezeigten Beispieldaten, Architekturen und Dashboards sind exemplarisch und ersetzen keine auf Ihre Situation zugeschnittene Analyse. Wenn Sie Ihre konkrete AI-Kostensituation einordnen möchten, sprechen wir gerne als Sparringspartner mit Ihnen über Architektur, Limits und Enablement. Kontaktieren Sie uns für ein unverbindliches Gespräch.

Kai Herings
Leitender Berater
Optimieren Sie die Abstimmung zwischen IT und Geschäft mit Expertenrat und klaren Strategien.